pandas vs polars vs cudf 速度比較
環境
CPU : Ryzen 7 3700X
GPU : RTX3090
OS : Windows11 / WLS2(Ubuntu 20.04)
(GPUとCPUのスペック差ありすぎだろというのは承知してますが、許してください。)
ライブラリ
pandas : 1.3.5
polars : 0.15.16
cudf : 21.10.01
定義
カテゴリ_カラム数:groupbyやmergeで使うkeyの数(※行数が増えるとカテゴリの数は増えます。)
集計先_カラム数:上記のカラム以外のカラムの数。groupbyなどで平均値などが算出されるカラム
比較
groupby
行数の変化
コード例
df.groupby(['Category']).mean()
カテゴリ_カラム数:1固定
集計先_カラム数:1固定
| 行数 | pandas | polars | cudf |
|---|---|---|---|
| 10000 | 0.002895 | 0.003179 | 0.005933 |
| 100000 | 0.012538 | 0.018462 | 0.006192 |
| 1000000 | 0.040214 | 0.075114 | 0.008816 |
| 10000000 | 0.260392 | 0.196927 | 0.176728 |
| 100000000 | 2.463650 | 1.327975 | 0.439283 |

集計先_カラム数の変化
コード例
df.groupby(['Category']).mean()
行数:10000000固定
カテゴリ_カラム数:1固定
| 集計先_カラム数 | pandas | polars | cudf |
|---|---|---|---|
| 1 | 0.227775 | 0.224480 | 0.031103 |
| 3 | 0.375450 | 0.459507 | 0.276226 |
| 5 | 0.675405 | 0.719819 | 0.258477 |
| 10 | 1.743981 | 0.303561 | 0.243129 |
| 15 | 2.435381 | 0.445725 | 0.269769 |
| 20 | 2.997430 | 0.609127 | 0.406935 |
| 30 | 4.019127 | 0.829848 | 0.431432 |
| 40 | 4.816778 | 1.073103 | 0.566872 |
| 50 | 5.497594 | 1.385903 | 0.712177 |
| 100 | 10.140957 | 2.753827 | 1.376491 |

カテゴリ_カラム数の変化
コード例
df.groupby(['Category_1','Category_2','Category_3',....]).mean()
行数:10000000固定
集計先_カラム数:5固定
| カテゴリ_カラム数 | pandas | polars | cudf |
|---|---|---|---|
| 1 | 0.615917 | 0.709272 | 0.080656 |
| 3 | 6.353710 | 1.244360 | 0.162426 |
| 5 | 12.523329 | 1.302869 | 0.180611 |
| 10 | 23.849953 | 1.410841 | 0.211472 |
| 15 | 32.821716 | 1.651729 | 0.248150 |
| 20 | 44.934443 | 1.874358 | 0.281277 |
| 30 | 63.756392 | 2.442004 | 0.345713 |
| 40 | 4.620836 | 2.987966 | 0.413109 |
| 50 | 102.124335 | 3.300031 | 1.089583 |
| 100 | 202.512414 | 5.987283 | 0.823975 |

merge
行数の変化
コード例
df1.merge(df2,how='left',on=['Category'])
カテゴリ_カラム数:1固定
集計先_カラム数:1固定
| 行数 | pandas | polars | cudf |
|---|---|---|---|
| 10000 | 0.003870 | 0.014977 | 0.004031 |
| 100000 | 0.019835 | 0.007815 | 0.005661 |
| 1000000 | 0.831185 | 0.167473 | 0.222576 |
| 5000000 | 17.477180 | 7.839335 | 1.170907 |
| 10000000 | 67.696730 | 32.517109 | Out of Memory |

カテゴリ_カラム数の変化
コード例
df1.merge(df2,how='left',on=['Category_1','Category_2','Category_3',....])
行数:100000固定
集計先_カラム数:5固定
| カテゴリ_カラム数 | pandas | polars | cudf |
|---|---|---|---|
| 1 | 0.029654 | 0.029583 | 0.013971 |
| 3 | 0.036057 | 0.009770 | 0.007494 |
| 5 | 0.052946 | 0.009572 | 0.008975 |
| 10 | 0.108638 | 0.009084 | 0.026948 |
| 15 | 0.148352 | 0.009819 | 0.034198 |
| 20 | 0.204366 | 0.010366 | 0.019411 |
| 30 | 0.301510 | 0.010791 | 0.049016 |
| 40 | 0.401895 | 0.011617 | 0.065830 |
| 50 | 0.497233 | 0.011856 | 0.060512 |
| 100 | 1.006292 | 0.015121 | 0.155082 |
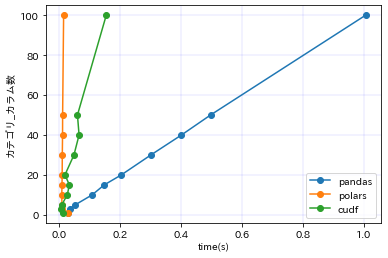
cudfよりpolarsのほうが早いという面白結果になりました。
強化学習でスーパーマリオ1-1をクリアする

本記事では、難しいことを考えずとりあえず便利なツールを使ってAIにスーパーマリオ1-1をクリアさせたいと思います。
スーパーマリオのROMを自分で用意する必要もありませんし、難しいアルゴリズムも理解する必要がありません。
「とにかく動かしたい!」という人向けです。
前提
・pythonを書ける。
・OpenAI Gymを知っている。
実行環境を作る
利用言語:python3.6
必要なライブラリ
・gym
・stable_baselines
・gym_super_mario_bros
・tensorflow==1.14.0(stable_baselinesが2.Xに対応してないようです。)
・pyqt5
・imageio
Open AI Gymのインストール方法
gym.openai.com
stable_baselinesのインストール方法
github.com
gym_super_mario_brosのインストール方法
github.com
tensorflow/pyqt5/imageioのインストール方法
$ pip install tensorflow==1.14.0 $ pip install pyqt5 $ pip install imageio
Stable Baselinesとは
Stable Baselineは、Open AIが提供する「OpenAI Baselines」の改良版です。
OpenAI Baselinesとは強化学習アルゴリズムの実装セットライブラリで、難しいアルゴリズムを簡単にゲームに応用することができます。
Stable BaselineとOpenAI Baselinesの比較は以下の様になっているそうです。

スーパーマリオの環境を見てみる
学習させるためにはまず環境が必要になります。
今回はインストールしたgym_super_mario_brosを使って環境を作ります。
以下を実行してみてください。
from nes_py.wrappers import JoypadSpace import gym_super_mario_bros from gym_super_mario_bros.actions import SIMPLE_MOVEMENT env = gym_super_mario_bros.make('SuperMarioBros-v0') env = JoypadSpace(env, SIMPLE_MOVEMENT) done = True for step in range(5000): if done: state = env.reset() state, reward, done, info = env.step(env.action_space.sample()) env.render() env.close()
おそらくこのような画面が出てきたと思います。これが今回学習する環境となります。
今回はランダムに動作をさせているので適当な動きをしています。

環境を作る
画像処理
上記の環境ではそのまま学習を行ってもなかなかうまく学習が進まないことが多いです。
そのため、上記の画面をAIが学習しやすいように処理をしてやります。
試行錯誤の結果以下で学習がうまく行きました。
from nes_py.wrappers import JoypadSpace import gym_super_mario_bros from gym_super_mario_bros.actions import SIMPLE_MOVEMENT,RIGHT_ONLY from stable_baselines.common.vec_env import DummyVecEnv from baselines.common.retro_wrappers import * from stable_baselines.bench import Monitor def make_env(): env = gym_super_mario_bros.make('SuperMarioBros-v3') # 画像荒く env = JoypadSpace(env, RIGHT_ONLY) # env = CustomRewardAndDoneEnv(env) # 報酬とエピソード完了の変更 <- 後ほど説明 env = StochasticFrameSkip(env, n=4, stickprob=0.25) # スティッキーフレームスキップ env = Downsample(env, 2) # ダウンサンプリング env = FrameStack(env, 4) # フレームスタック env = ScaledFloatFrame(env) # 状態の正規化 env = Monitor(env, log_dir, allow_early_resets=True) env.seed(0) # シードの指定 set_global_seeds(0) env = DummyVecEnv([lambda: env]) # ベクトル環境の生成 return env env = make_env() done = True for step in range(5000): if done: state = env.reset() env.render() env.close()
以下のような画面が出てきたかと思います。
もはや、「マリオとは・・」という感じですがこのような画像処理が大事になります。

報酬の設定
報酬などの説明は以下の記事を参考にしてください。
qiita.com
上記のコード内のここで報酬を設定しています。
env = CustomRewardAndDoneEnv(env) # 報酬とエピソード完了の変更 <- 後ほど説明
ここでは、マリオの位置が前回の位置よりも右にあれば報酬を+1,それ以外であれば報酬を-1にしています。
また、Goalをすると報酬を+2にしています。
# CustomRewardAndDoneラッパー class CustomRewardAndDoneEnv(gym.Wrapper): # 初期化 def __init__(self, env): super(CustomRewardAndDoneEnv, self).__init__(env) self._cur_x = 0 self._max_x = 0 self.reward = 0 # リセット def reset(self, **kwargs): self._cur_x = 0 self._max_x = 0 self.reward = 0 return self.env.reset(**kwargs) # ステップ def step(self, action): state, reward, done, info = self.env.step(action) # 報酬の変更 if (info['x_pos'] > self._cur_x) & (self._cur_x != 0): # reward += 1 self.reward += 1 else: # reward -= 1 self.reward -= 1 self.reward /= 1000 self._cur_x = info['x_pos'] if info['life'] <= 1: self.reward -= 0.3 if info['life'] == 1: done = True # エピソード完了の変更 if info['flag_get']: self.reward += 2 done =True print('GOAAL') return state, self.reward, done, info
学習させる
github.com
上記のコードをcloneして、以下を実行すればとりあえず学習が始まると思います。
$ python mario_baseline.py
mario_baseline.py
from nes_py.wrappers import JoypadSpace import gym_super_mario_bros from gym_super_mario_bros.actions import SIMPLE_MOVEMENT,RIGHT_ONLY import time from stable_baselines import PPO2,DQN from stable_baselines.common.policies import CnnPolicy from stable_baselines.common.vec_env import DummyVecEnv from baselines.common.retro_wrappers import * from stable_baselines.bench import Monitor from util import CustomRewardAndDoneEnv,log_dir,CustomCallback from stable_baselines.common import set_global_seeds from stable_baselines.common.callbacks import * from stable_baselines.deepq.policies import CnnPolicy as DQNCnnPolicy def make_env(): env = gym_super_mario_bros.make('SuperMarioBros-v3') env = JoypadSpace(env, RIGHT_ONLY) env = CustomRewardAndDoneEnv(env) # 報酬とエピソード完了の変更 env = StochasticFrameSkip(env, n=4, stickprob=0.25) # スティッキーフレームスキップ env = Downsample(env, 2) # ダウンサンプリング # env = Rgb2gray(env) # グレースケール env = FrameStack(env, 4) # フレームスタック env = ScaledFloatFrame(env) # 状態の正規化 env = Monitor(env, log_dir, allow_early_resets=True) env.seed(0) # シードの指定 set_global_seeds(0) env = DummyVecEnv([lambda: env]) # ベクトル環境の生成 print('行動空間: ', env.action_space) print('状態空間: ', env.observation_space) return env env = make_env() custom_callback = CustomCallback(env,render=True) model = PPO2(policy=CnnPolicy, env=env, verbose=0,learning_rate=0.000025,tensorboard_log=log_dir) # モデル定義 model.learn(total_timesteps=2000000, callback=custom_callback) # 学習 model = PPO2.load('./agents/best_mario_ppo2model', env=env, verbose=0) # ベストなモデルを読み込む state = env.reset() total_reward = 0 while True: # 環境の描画 env.render() # スリープ time.sleep(1/25) # モデルの推論 action, _ = model.predict(state) # 1ステップ実行 state, reward, done, info = env.step(action) total_reward += reward[0] # エピソード完了 if done: print('reward:', total_reward) state = env.reset() total_reward = 0 # state = env2.reset()
学習はPCのスペックにもよりますが普通のPCだと12時間程度かかるかと思います。
学習の過程はtensorboradを用いることで以下のように確認できます。
$ tensorboard --logdir=./logs/
「http://localhost:6006」にアクセスすれば以下のような画面が出てくるかと思います。

学習がうまく行っていれば、rewardが徐々に上がっていくかと思います。(学習がうまく行かない場合は報酬や画像処理の見直しをおすすめします)
学習後
私の環境では、2~3回に1回ゴールするようになりました。

自分のAIがゲームをクリアするの嬉しいですね😢
おわりに
今回は強化学習を用いてスーパーマリオ1-1をクリアしました。
みなさんも、自分なりに報酬を変更したりして試して見てください。
OpenAI Gymなどの他のゲームも試してみると面白いと思います!👾
参考
OpenAI Gym / Baselines 深層学習・強化学習 人工知能プログラミング 実践入門 | 布留川 英一, 佐藤 英一 |本 | 通販 | Amazon
MicrosoftのInterpretMLが便利だった
本記事では、Microsoftが開発しているInterpretMLを紹介をします。
目次
InterpretMLとは
InterpretMLとは、機械学習の解釈を説明可能とするためのpythonライブラリです。(英語だと machine learning inter-pretability algorithms )
最先端の機械学習アルゴリズム(ニューラルネットやGBDTなど)は精度が高い一方で、実際に中でどのようにデータを解釈し結果を出しているかがブラックボックス化されてしまっています。
実際、仕事でも機械学習アルゴリズムがデータをどのように解釈して結果を出しているか説明を求められる場合などもありますし、精度が高くても中身を説明できないものは使わないという現場もあるようです。
一方で線形モデルのように、アルゴリズムがどのようにデータを解釈し結果を出しているのかがわかるものをグラスボックス(Glassbox)と言います。
そして、InterpretMLはこのグラスボックス化されたアルゴリズムをパッケージ化してアルゴリズムの解釈を様々な図として表現できるようにしたライブラリです。
しかし、グラスボックス化されたアルゴリズムは最先端の機械学習アルゴリズムと比較して精度が低い場合が多いです。
InterpretMLではこの「グラスボックス化されたアルゴリズムの精度が低い」というデメリットを解消した、Explainable Boosting Machine(EBM)
とよばれる新しいモデルを含んでいます。

github.com
※まだ、α版
Explainable Boosting Machine(EBM)
EBMは、上記にも記載をしたように「グラスボックス」かつ「高精度」を実現した機械学習アルゴリズムです。
この資料にもあるように、実際にLightGBMと同等もしくはそれ以上の精度がでるようです。

精度と解釈で見ると以下のようにまとめることができます。
| GBDT | NN | LR | EBM | |
|---|---|---|---|---|
| 精度 | ◯ | ◯ | △ | ◯ |
| 解釈 | ☓ | △ | ◯ | ◯ |
これは、実際に使ってみて試したくなりますね。
実際に使ってみる
参考資料
Model Interpretation with Microsoft’s Interpret ML | by Mayur Sand | Analytics Vidhya | Medium
利用データ
Titanic: Machine Learning from Disaster | Kaggle
コード
GitHub - zakopuro/example_interpret
インストール
interpretMLは以下のようにpipで簡単にinstallできます。
pip install interpret
データを確認する
interpretMLでは簡易にデータを確認できます。(現在は欠損値に対応してないので注意)
from interpret import show from interpret.data import ClassHistogram,Marginal from interpret.glassbox import ExplainableBoostingClassifier from sklearn.model_selection import train_test_split from interpret.perf import ROC import pandas as pd data = pd.read_csv("data/train.csv") # 欠損値をサポートしてないようなので削除する X = data.drop(['Survived','Cabin','Embarked','Age'],axis=1) y = data['Survived'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) hist = ClassHistogram().explain_data(X_train, y_train, name = 'Train Data') show(hist)
上記をjupyter notebook上で実行すると以下のようなグラフが表示されます。
これは、ターゲットとなるデータのヒストグラムです。

図のSummaryと書かれている部分を選択すると以下のように各カラムを選択することができ、それぞれのデータを簡易に確認することができます。(便利)


学習
EBMで学習してみます。ラベルエンコーダーなどの必要もないらしい。簡単。
(※Lightgbmなどと比較すると結構学習時間がかかるかも・・)
ebm = ExplainableBoostingClassifier(random_state=42)
ebm.fit(X_train, y_train)
モデルの解釈の可視化
EBMの特徴である、モデルのデータの解釈を可視化も非常に簡単にできます。
ebm_global = ebm.explain_global(name='EBM')
show(ebm_global)
SummaryではLightgbmなどでもおなじみの特徴量重要度(Feature importance)を確認できます。

他にも、特徴毎にその特徴量のどんな値が学習に影響を与えたかも可視化することができます。
例えば、下図はFare(運賃)の特徴量の解釈図ですが、おおよそ510以上になっているFareが特徴量として大きな影響を与えていることがわかります。

また、testデータに対しての解釈も以下のように確認できます。
ebm_local = ebm.explain_local(X_test, y_test, name='EBM')
show(ebm_local)
すべての予測データに対してどの特徴量がプラスに働いて、どの特徴量がマイナスに働いたかを可視化することができます。
例えば、以下の図では71行目のデータはSexやPclassは結果にプラスに働いたが、Ticketなどはマイナスに働いたことがわかります。

ROC曲線も簡単に可視化できます。
ebm_perf = ROC(ebm.predict_proba).explain_perf(X_test, y_test, name="EBM")
show(ebm_perf)

まとめ
今回は、InterpretMLを紹介しました。
機械学習アルゴリズムの解釈という点では非常に使いやすくわかりやすい印象です。
しかし、まだα版ということもありドキュメントが充実していなかったり、学習時間が長かったりと改善してほしい点(自分でプルリクしろ)はいくつかありました。
ただ、そこが改善されればLightgbmやxgboostなどにおきかわるライブラリになる可能性もあると思いました。
時系列予測で使えるpythonライブラリ一覧
本記事では、時系列予測に利用できるpythonのライブラリの使い方について説明をします。
パッとライブラリを使うことを目指すため具体的なアルゴリズムの説明は省きます。
※説明が間違えている場合があればご指摘いただけると助かります。
目次
利用データ
ライブラリ
Prophet
PyFlux
Pyro
Pytorch
Lightgbm
補足:Darts
まとめ
ソースコード
このブログで記載されているソースコードはGitHubに上げておいたのでもしよろしければ参考にしてください。
github.com
利用データ
今回用いるデータはkaggleのM5 Forecasting - Accuracyと呼ばれるコンペティションで利用されたデータを用います。
作成したランダムなデータよりも実データのほうが予測をしている感があるからです。
予測に使うデータはwalmartの売上データです。
下図はそのデータをplotしたものです。
売上が0になっている日がありますが、この日付を見ると12/25になっています。
アメリカではクリスマスは休日なのでwalmartもお休みのようです。
 こちらのデータの最後28個(28日間)のデータを予測します。
こちらのデータの最後28個(28日間)のデータを予測します。
下の図は最後の56個のデータをplotしたものです。
 曜日による周期があるように見えます。
曜日による周期があるように見えます。
では、こちらのデータを様々なライブラリで予測してみようと思います。
ライブラリ一覧
Prophet
Prophetはfacebookが開発している時系列解析ライブラリです。
トレンドの変化を確認したり、モデル作成時に周期やイベント効果を追加することができます。
公式ドキュメント
facebook.github.io
参考ブログ
時系列解析ライブラリProphet 公式ドキュメント翻訳1(概要&特徴編) - Qiita
データの準備
Prophetでは、データをpandasのDataFrameで渡す必要があります。
そして、このDataFrameには2つのカラムが必要です。
2つのカラムはそれぞれ"y","ds"と名前をつける必要があります。
y : 予測したい値(数値)
ds : YYYY-MM-DD フォーマットになっている日付データ。(datestamp,strどちらでも可)
具体的には以下の様になっている必要があります。
| y | ds |
|---|---|
| 123 | 2018-1-1 |
| 111 | 2018-1-2 |
| 144 | 2018-1-3 |
| 156 | 2018-1-4 |
モデルの定義/学習
model = Prophet() # 月と週の周期を追加 model.add_seasonality(name='monthly', period=28, fourier_order=5) model.add_seasonality(name='weekly', period=7, fourier_order=5) # 学習 model.ft(data)
予測
予測をする際は、どれくらい先まで予測をするのかを決めることができます。
future_data = model.make_future_dataframe(periods=28, freq='D') forecast_data = model.predict(future_data) #予測
予測結果
予測結果を確認する方法はいくつかありますが、今回はforecast_dataに格納されているデータを用いて確認をします。
また、forecast_dataにはトレンドや周期情報なども格納されています。
plt.figure(figsize=(20,5)) plt.plot(df['y'][-56:],label='true') plt.plot(forecast_data['yhat'][-84:],label='pred') plt.legend() plt.show()

精度としてはすごく良いものではないかもしれないですが形は捉えることができています。
簡単に時系列予測をするときは便利なライブラリです。
以下のように簡単にトレンドや周期も確認できます。
model.plot_components(forecast_data)

PyFlux
※現在、PyFluxはメンテナンスを停止しており、Python3.6以降には対応していないようです。
利用の際はご注意ください。(他のライブリラを利用することを推奨します。)
PyFluxは時系列予測のためのライブラリで、確率分布を用いたアプローチをしているようです。
ドキュメント
pyflux.readthedocs.io
参考記事
時系列データの予測ライブラリ--PyFlux-- - Qiita
データの準備
PyFluxでは時系列データをそのまま扱うことができます。
なので、事前に必要な準備は特にありません。
モデルの定義
pyfluxではARIMAやARIMAXなどのモデルが使えますが、今回はARIMAモデルを使いたいと思います。
以下のように非常にシンプルに書けます。
arima_model = pf.ARIMA(data=data, ar=8, ma=8, target='sunspot.year', family=pf.Normal())
学習
学習も非常にシンプル。
summaryの確認もできます。
x = model.fit("MLE")
x.summary()
Normal ARIMA(8,0,8) ======================================================= ================================================== Dependent Variable: Series Method: MLE Start Date: 8 Log Likelihood: -18498.7318 End Date: 1940 AIC: 37033.4637 Number of observations: 1933 BIC: 37133.6666 ========================================================================================================== Latent Variable Estimate Std Error z P>|z| 95% C.I. ======================================== ========== ========== ======== ======== ========================= Constant 34480.769 3412.7463 10.1035 0.0 (27791.7863 | 41169.7517) AR(1) -0.4931 0.0673 -7.3239 0.0 (-0.625 | -0.3611) AR(2) -0.1625 0.0295 -5.5125 0.0 (-0.2203 | -0.1048) AR(3) -0.1608 0.0289 -5.5687 0.0 (-0.2174 | -0.1042) AR(4) -0.0973 0.0269 -3.6126 0.0003 (-0.1501 | -0.0445) AR(5) -0.2247 0.0335 -6.7046 0.0 (-0.2904 | -0.159) AR(6) -0.0474 0.0274 -1.7302 0.0836 (-0.1011 | 0.0063) AR(7) 0.7559 0.0363 20.8272 0.0 (0.6847 | 0.827) AR(8) 0.4058 0.0662 6.1256 0.0 (0.276 | 0.5357) MA(1) 0.9191 0.0639 14.3768 0.0 (0.7938 | 1.0444) MA(2) 0.6648 0.0479 13.8649 0.0 (0.5708 | 0.7587) MA(3) 0.6405 0.045 14.2294 0.0 (0.5523 | 0.7287) MA(4) 0.5536 0.0441 12.564 0.0 (0.4672 | 0.6399) MA(5) 0.6257 0.0455 13.762 0.0 (0.5366 | 0.7149) MA(6) 0.504 0.0364 13.8621 0.0 (0.4328 | 0.5753) MA(7) -0.1486 0.0541 -2.744 0.0061 (-0.2547 | -0.0425) MA(8) -0.1788 0.0408 -4.3821 0.0 (-0.2588 | -0.0988) Normal Scale 3467.0383 ==========================================================================================================
予測
予測結果も簡易的に確認できます。
(あまりうまく予測はできていないようですが?…)
model.plot_predict(h=28, past_values=56, figsize=(15,5))

Pyro
PyroはPyTorchをベースにした確率プログラミングのフレームワークです。
なのでpyroを利用するにはまずPyTorchをインストールする必要があります。
公式ドキュメント
pyro.ai
参考ブログ
Pyro on PyTorch の時系列モデリングが超進化していた【HMM】 - HELLO CYBERNETICS
データの準備
pyroでは予測データと共変量(特徴量みたいなイメージ)の準備をします。
今回は、日にちをone hotした値をday_of_monthに格納して入れます。
T0 = 0 # start T2 = data.size(-2) + 28 # end 28日後まで予測 time = torch.arange(T0, float(T2), device="cpu") / 365 # 共変量(特徴量みたいなイメージ) covariates = torch.cat([ time.unsqueeze(-1), day_of_month, ], dim=-1)
モデルの定義
pyro.contrib.forecastにあるForecastingModelクラスを継承して実装します。
ここで必要になるのは、model(self, zero_data, covariates) というメソッドです。
model メソッドは戻り値が不要で、内部で self.predict(noise_dist, prediction) が呼ばれていればOKです。
class Model(ForecastingModel): def model(self, zero_data, covariates): assert zero_data.size(-1) == 1 # univariate duration = zero_data.size(-2) time, feature = covariates[..., 0], covariates[..., 1:] bias = pyro.sample("bias", dist.Normal(0, 10)) # construct a linear trend; we know that the sales are increasing # through years, so a positive-support prior should be used here trend_coef = pyro.sample("trend", dist.LogNormal(-2, 1)) trend = trend_coef * time # set prior of weights of the remaining covariates weight = pyro.sample("weight", dist.Normal(0, 1).expand([feature.size(-1)]).to_event(1)) regressor = (weight * feature).sum(-1) # encode the additive monthly seasonality with pyro.plate("month",28,dim=-1): seasonal = pyro.sample("seasonal_1", dist.Normal(0, 7)) seasonal = periodic_repeat(seasonal, duration, dim=-1) # make prediction prediction = bias + trend + seasonal + regressor prediction = prediction.unsqueeze(-1) # Now, we will use heavy tail noise because the data has some outliers # (such as Christmas day) dof = pyro.sample("dof", dist.Uniform(1, 10)) noise_scale = pyro.sample("noise_scale", dist.LogNormal(-2, 1)) noise_dist = dist.StudentT(dof.unsqueeze(-1), 0, noise_scale.unsqueeze(-1)) self.predict(noise_dist, prediction)
学習
学習では、Forecasterに上記で作成したモデル,データ,共変量,ハイパーパラメータを渡すことで可能です。
戻り値は学習が終了済の予測推論ができるようになっているインスタンスになっています。
seedの設定もできるようです。
pyro.set_rng_seed(127) forecaster_options = { "learning_rate": 0.1, "learning_rate_decay": 0.1, "clip_norm": 10, "num_steps": 1001, "log_every": 100, } forecaster = Forecaster(Model(), data, covariates[:-28], **forecaster_options)
予測
forecasterにデータと共変量(予測先も含めた)とサンプルサイズを渡すことで予測が可能です。
サンプルサイズだけ予測結果を出す(quantileを取ることで予測区間を確認することができる)ため今回は平均値を予測値としました。
samples = forecaster(data, covariates, num_samples=2000).exp().squeeze(-1).cpu() pred = samples.mean(0) quantiles = [0.005, 0.025, 0.165, 0.25, 0.5, 0.75, 0.835, 0.975, 0.995] q_pred = np.quantile(samples,quantiles,axis=0)

 ※赤いところが0.5〜99.5%の予測区間
※赤いところが0.5〜99.5%の予測区間
Pytorch(LSTM)
Pytorchは皆さんご存知ニューラルネットの作成に利用されるライブラリです。(もちろんTensorflow,kerasでもOK)
ニューラルネットにも時系列に特化したネットワークが存在します。RNNやTransformerなどもありますが、今回はLSTMのみの実装とします。
公式ドキュメント
pytorch.org
データの準備
データは少し変わった(?)用意の仕方をします。
以下のような時系列データがあった場合、

赤い線を説明変数、緑の点を目的変数として扱います。
今回は28日後までを予測させるため28日後を目的変数としました。
もちろん説明変数には時系列データ以外にも曜日等のデータを特徴量として加えることができます。

def sliding_windows(data, seq_length , train): if train: x = [] y = [] for i in range(len(data)-seq_length*2): _x = data[i:(i+seq_length)] _y = data[i+(seq_length*2)] x.append(_x) y.append(_y) return np.array(x),np.array(y)[:,0].reshape(-1,1) else: x = [] for i in range(len(data)-seq_length+1): _x = data[i:(i+seq_length)] x.append(_x) return np.array(x) seq_length = 28 x, y = sliding_windows(data, seq_length, True) trainX = Variable(torch.Tensor(np.array(x[0:-28]))) trainY = Variable(torch.Tensor(np.array(y[0:-28]))) valX = Variable(torch.Tensor(np.array(x[-28:]))) valY = Variable(torch.Tensor(np.array(y[-28:])))
モデルの定義
私自身、ニューラルネットはあまり詳しくないですが、モデルの定義方法や学習方法は一般的なニューラルネットを学習するときと変わらないです。
class LSTM(nn.Module): def __init__(self, num_classes, input_size, hidden_size, num_layers): super(LSTM, self).__init__() self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') self.num_classes = num_classes self.num_layers = num_layers self.input_size = input_size self.hidden_size = hidden_size self.batch_size = 1 self.LSTM = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers,batch_first=True,dropout = 0.25) self.fc = nn.Linear(hidden_size, num_classes) self.dropout = nn.Dropout(p=0.2) def forward(self, x): h_1 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(self.device)) c_1 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(self.device)) _, (hn, cn) = self.LSTM(x, (h_1, c_1)) y = hn.view(-1, self.hidden_size) final_state = hn.view(self.num_layers, x.size(0), self.hidden_size)[-1] out = self.fc(final_state) return out device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') num_epochs = 200 learning_rate = 1e-3 input_size = x.shape[-1] hidden_size = 512 num_layers = 3 num_classes = 1 lstm = LSTM(num_classes, input_size, hidden_size, num_layers) lstm.to(device) criterion = torch.nn.MSELoss().to(device) optimizer = torch.optim.Adam(lstm.parameters(), lr=learning_rate,weight_decay=1e-5) scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=100, factor =0.5 ,min_lr=1e-7, eps=1e-08)
学習
for epoch in tqdm(range(num_epochs)): lstm.train() outputs = lstm(trainX.to(device)) optimizer.zero_grad() # obtain the loss function loss = criterion(outputs, trainY.to(device)) loss.backward() optimizer.step() #Evaluate on test lstm.eval() valid = lstm(valX.to(device)) vall_loss = criterion(valid, valY.to(device)) scheduler.step(vall_loss) if epoch % 50 == 0: print("Epoch: %d, loss: %1.5f valid loss: %1.5f " %(epoch, loss.cpu().item(),vall_loss.cpu().item()))
予測
x = sliding_windows(data, seq_length, False)
testX = Variable(torch.Tensor(np.array(x)))
train_predict = lstm(testX.to(device))

ニューラルネットでも簡単(?)に時系列予測ができます。
Lightgbm(GBDT)
Lightgbmが時系列予測ライブラリ?と思った方もいるかもしれないですが、特徴量をうまく入れることで予測は可能です。
しかし、上記のライブラリのように過去のデータから時系列的に予測するということは行っていません。あくまで、過去のデータを特徴量として扱うことで予測をします。
ドキュメント
lightgbm.readthedocs.io
データの準備
以下が時系列系でよく利用する特徴量です。(今回は28日後までを予測するためlagは28を最小にしています。)
これ以外にも曜日,日付,平日,祝日,大型連休などの特徴量が効くことが多いです。
時系列予測では時系列データだけで予測しようとしがちですが使える特徴量はできるだけ使うのが無難だと思います。
for lag in [28,35,42,364]: df[f'lag_{lag}'] = df["target"].shift(lag) for lag in [28,35,42,364]: for win in [7,14]: df[f'win{win}_lag{lag}'] = df['target'].transform(lambda x: x.shift(lag).rolling(win).mean())
学習
時系列データ以外と同様の方法で学習させます。
trn_data = lgb.Dataset(train_df.drop('target',axis=1), label=train_df['target']) val_data = lgb.Dataset(valid_df.drop('target',axis=1), label=valid_df['target']) lgb_params = { 'boosting_type': 'gbdt', 'metric': 'rmse', 'objective': 'regression', 'seed': 127, 'early_stopping_rounds' : 500, 'learning_rate': 0.03 } lgb_model = lgb.train(lgb_params, trn_data, num_boost_round = 10000, valid_sets = [trn_data, val_data], verbose_eval=500)
予測
val_pred = lgb_model.predict(valid_df.drop('target',axis=1)) test_pred = lgb_model.predict(test_df.drop('target',axis=1))

こんなシンプルな特徴量だけでもそれっぽい予測ができました。さすがGBDT。
補足:Darts
上記以外のライブラリにDartsと呼ばれるライブラリがあるようです。
以下のモデルに対応しており、非常に便利そうです。
- Exponential smoothing
- ARIMA & auto-ARIMA
- Facebook Prophet
- Theta method
- FFT (Fast Fourier Transform)
- Recurrent neural networks (vanilla RNNs, GRU, and LSTM variants)
- Temporal convolutional network
詳しくは以下の記事を参考にしてみてください。
まとめ
時系列予測に使えるpythonのライブラリを紹介しました。
簡単に予測をすることができるライブラリが多くあって非常に便利でした。
特にProphetとPyFluxは非常に簡単に予測をすることができ、最初にパッと使うライブラリとして向いていると思います。
高度な予測をするには、Pyro,Pytorch,Lightgbm等を利用するのが良いかと思います。(過学習に気を付けて😨!!)